-
SR-GAN 정리 및 코드paper(논문 정리) 2021. 10. 6. 15:58
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network 라는 제목으로 CVPR2017에 올라간 논문입니다.
2017년에는 좋은 논문들이 많이 나온것 같네요!
SRGAN - Super Resolution + GAN
Super resolution 분야에서 사용된 GAN 모델이다.
Super Resolution은 해상도를 높이는 것을 의미한다.
고전의 방법으로는 bicubic, linear 같은 방법으로 보간법(interpolation) 주변의 픽셀을 활용해서 확장된 영역의 픽셀을 채웠다.
딥러닝이 나오고 CV영역에서는 고전의 방법으로 하던 작업을 딥러닝으로 옮기고자 한다.
많은 super resolution을 위한 모델들이 나왔고 GAN의 방법론을 가져와서 적용을 한다.
SRGAN 구조
구조를 봤을때는 단순하다는 생각이 들었습니다.

GAN구조이다 보니 당연하게도 generator과 discriminator 두개를 생성한다.
구조로는 쉽게 resnet에서 쉽게 볼 수 있는 skip connection을 사용하고 있습니다.
논문에서는 B residual blocks을 사용합니다.
(여러곳에서 residual blocks를 영감받았다고 합니다.)
http://torch.ch/blog/2016/02/04/resnets.html
Torch | Training and investigating Residual Nets
Torch is a scientific computing framework for LuaJIT.
torch.ch
https://arxiv.org/abs/1603.08155
Perceptual Losses for Real-Time Style Transfer and Super-Resolution
We consider image transformation problems, where an input image is transformed into an output image. Recent methods for such problems typically train feed-forward convolutional neural networks using a \emph{per-pixel} loss between the output and ground-tru
arxiv.org
그리고 일반적인 것과 다른 부분으로는 활성화 함수로 PReLU를 사용하고 있다는 점이다.
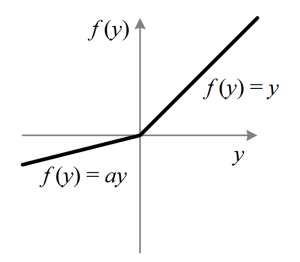
Relu와의 차이는 음수 영역에서도 a라는 parameter를 두어 사용합니다.
parameter이기 때문에 활성화 함수지만 train을 하면 같이 학습이 됩니다.
SR을 위한 network인데 특이한 점이 있습니다.
입력 이미지의 크기가 커지는 layer가 없습니다.
보통 Upsampling을 위해 deconvolution을 하는것이 일반적입니다. 그래야 h,w가 높은 이미지를 얻을 수 있기때문이죠.

SRCNN은 bicubic interpolation을 통해 해상도를 올린다음 입력이미지로 사용을 하고
FSRCNN은 마지막에 deconvolution layer를 사용합니다.
하지만 SRGAN에서는 h,w를 높여주는 layer가 없습니다. 그이유는 바로 sub-pixel convolution layers를 사용한다고 합니다.

sub-pixel convolution은 위와 같은 방법으로 진행이 되는데 여러개의 channel들을 셔플해서 사용하면 super resolution이 됩니다.
generator 끝부분에 보면 pixel shuffle가 있는 것을 확인할 수 있습니다.
discriminator은 특이점은 Relu 대신 이번에는 Leakey ReLU를 사용하는것입니다.
(사용한 이유에 특별한 이유가 없는것을 볼때 제 생각이지만 여러 방법으로 대체를 했을때 Leakey ReLU가 가장 좋은 성능을 보인것 같습니다.)
여기까지가 SRGAN의 구조에 대한 설명입니다.
SRGAN Loss
사실 구조같은 경우는 본 논문의 가장 큰 contribution은 Loss function이라고 생각됩니다.
Here we replace the MSE-based content loss with a loss calculated on feature maps of the VGG network [49], which are more invariant to changes in pixel space [38].
MSE based의 content loss대신 VGG network를 활용한 content loss로 대체 되었다고 설명하고 있습니다.
기존의 MSE-based loss는 점수는 좋을지 몰라도 받아들이기에는 좋지 못한 경우가 있다고 합니다.
pixel by pixel로 비교를 하기 때문에 아무래도 중간 값을 가지는 경향으로 되고 smooth가 된다고 합니다.
논문에서는 content loss를 다음과 같이 사용합니다.

SRGAN 전체 loss funtion 
perceptual loss content loss, adveresarial loss로 되어있음 
VGG loss 위의 사진에서 content loss에 해당함 
adversarial loss 위에서 부터 차례대로 한 부분씩 설명을 하는 부분입니다.
식은 복잡하지만 내용은 간단합니다.
(편의상 Low resolution image는 x high resolution image는 X로 표기하겠습니다. x가 super resolution된 image는 S라고 쓰겠습니다.)
G(x)는 작은 해상도를 넣었을때 generator을 거쳐서 나오는 Super resolution image가 됩니다.
I(S,X)가 됩니다 그럼 바로 밑에 식에 대입을 하면 됩니다.
I(S,X)는 또 두개로 나눠지게 되죠.
content loss와 adversarial loss 입니다. 두개의 loss함수에 각각 들어가게 됩니다.
content loss는 VGGloss라고 이름을 붙였습니다.
We define the VGG loss based on the ReLU activation layers of the pre-trained 19 layer VGG network
수식은 매우 어렵게 써있지만 의미를 파악하는데에는 어렵지 않습니다.
pretrained된 VGG19의 각 layer에 있는 활성화 함수와 maxpooling layer의 값들을 X를 넣었을때와 비교한다는 뜻입니다.
SR된 S가 X와 얼마나 유사한지 MSE-based방식보다 더 잘 표현할 수 있다고 합니다.
실험
실험은 여러 SR network와 비교를 했습니다.
고전적인 metric과도 비교를 했지만 MOS(Mean Opinion Score)로 사람이 평가하는 항목을 넣었습니다.
26명의 사람에게 직접 보여주어 자연스러운정도를 1~5점으로 표현하게 했습니다.

실험 결과를 보면 SRGAN이 PSNR이나 SSIM 점수는 다소 낮은 것을 확인 할 수 있습니다.
반면에 사람이 직접 평가한 MOS는 더 높은 점수를 얻은것을 볼 수 있습니다.
이것이 의미하는 바는 정략적인 metric보다 사람이 직접 평가했을때 더 품질이 좋아 보인다는 것을 의미한다고 볼 수 있습니다.
(물론 26명의 사람의 표본이 많다고는 볼 수 없지만 꽤 많은 차이가 남을 확인할 수 있습니다.)
결론적으로 주장하고 싶은 이야기는 SSIM, PSNR 점수가 높다고 정말 Super resolution이 잘됐다고는 말할 수 없다는 것을 의미하는 것 같습니다.
'paper(논문 정리)' 카테고리의 다른 글
Efficient net 정리 (0) 2021.10.04 FCN 논문 생각 정리 (0) 2021.10.04 UNIT (Unsupervised Image to Image Translation Network) (0) 2021.04.27