-
VGG-16, VGG-19 Tensorflow 구현pytorch & tensorflow 2021. 9. 29. 17:12

vgg 구조 VGGNet의 구조
1. 가장 기본 적인 구조로 모든 conv필터가 3x3이다.
매우 간단한 구조를 가지면서 꽤 좋은 성능을 보이기 때문에 비교군으로 혹은 테스트를 할때 애용된다.
2. vgg는 블럭형태가 반복되면서 들어가는 것을 확인 할 수 있다.
두개혹은 세개의 conv필터와 maxpooling을 블럭단위로 연속해서 쌓는 방식으로 진행된다.
블럭을 지날수록 필터의 크기는 반으로 줄어들게 한다. (conv필터는 padding = same을 하지만 maxpooling에 의하여 줄어듦)
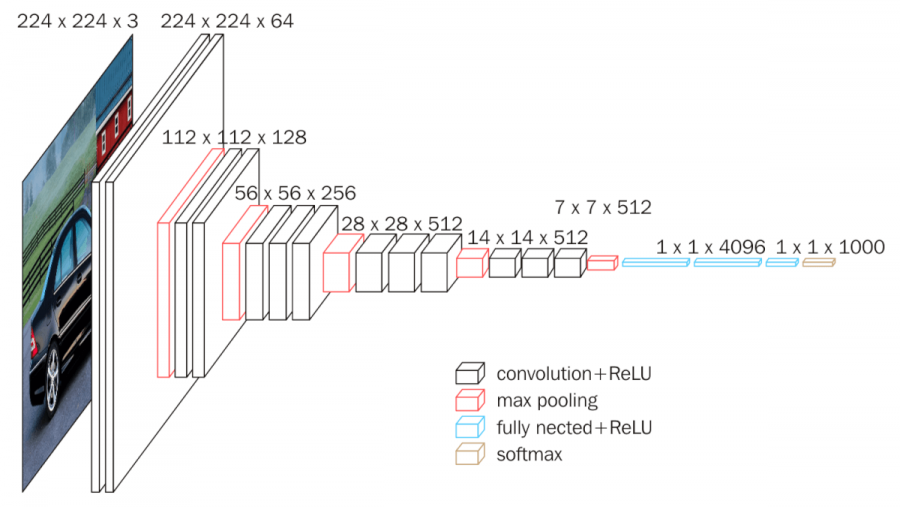
vgg net 구조 Tensorflow 구현
cifar-10을 활용하여 vgg를 구현한뒤 테스트 해봤다.
데이터 로드부분은 생략하고 바로 코드 블럭을 구현한다.
vgg 블럭 구현
def build_vgg_block(input_layer, num_cnn=3, channel=64, block_num=1, ): # 입력 레이어 x = input_layer # num_cnn : 한블럭에서 사용할 conv필터 개수 네트워크에 따라 2개일때가 있고 3개일때가 있음. # CNN 레이어 for cnn_num in range(num_cnn): x = keras.layers.Conv2D( filters=channel, kernel_size=(3,3), activation='relu', kernel_initializer='he_normal', padding='same', name=f'block{block_num}_conv{cnn_num}' )(x) # Max Pooling 레이어 x = keras.layers.MaxPooling2D( pool_size=(2, 2), strides=2, name=f'block{block_num}_pooling' )(x) return x구조는 간단하며 conv필터를 num_cnn개수만큼 쌓은뒤 maxpooling을 뒤에 쌓아서 한 블럭을 만든다.
default옵션으로 했을 경우 아래와 같다.

vgg block default 구조 블럭을 만들었으면 블럭을 불러올 함수가 필요하다.
vgg builder 구현
def build_vgg(input_shape=(32,32,3), num_cnn_list=[2,2,3,3,3], channel_list=[64,128,256,512,512], num_classes=10): assert len(num_cnn_list) == len(channel_list) #모델을 만들기 전에 config list들이 같은 길이인지 확인합니다. input_layer = keras.layers.Input(shape=input_shape) # input layer를 만들어둡니다. output = input_layer # config list들의 길이만큼 반복해서 블록을 생성합니다. for i, (num_cnn, channel) in enumerate(zip(num_cnn_list, channel_list)): output = build_vgg_block( output, num_cnn=num_cnn, channel=channel, block_num=i ) output = keras.layers.Flatten(name='flatten')(output) output = keras.layers.Dense(4096, activation='relu', name='fc1')(output) output = keras.layers.Dense(4096, activation='relu', name='fc2')(output) output = keras.layers.Dense(num_classes, activation='softmax', name='predictions')(output) model = keras.Model( inputs=input_layer, outputs=output ) return modelnum_classes는 10으로 cifar-10 데이터셋을 사용했기 떄문이다. (다른 분류를 한다면 숫자를 클래스에 맞게 변경해주면된다.)
Input layer - vgg block - classification layer 순으로 배치를 하면 vgg완성이다.
vgg-19로 만들고 싶으면 builder의 파라미터만 변경해주면 된다.
vgg_19 = build_vgg( num_cnn_list=[2,2,4,4,4], channel_list=[64,128,256,512,512] )Result
20에폭으로 학습을 진행한다.
vgg_16.compile( loss='sparse_categorical_crossentropy', optimizer=tf.keras.optimizers.SGD(lr=0.01, clipnorm=1.), metrics=['accuracy'], ) history_16 = vgg_16.fit( ds_train, steps_per_epoch=int(ds_info.splits['train'].num_examples/BATCH_SIZE), validation_steps=int(ds_info.splits['test'].num_examples/BATCH_SIZE), epochs=EPOCH, validation_data=ds_test, verbose=1, use_multiprocessing=True, )vgg_19.compile( loss='sparse_categorical_crossentropy', optimizer=tf.keras.optimizers.SGD(lr=0.01, clipnorm=1.), metrics=['accuracy'], ) history_19 = vgg_19.fit( ds_train, steps_per_epoch=int(ds_info.splits['train'].num_examples/BATCH_SIZE), validation_steps=int(ds_info.splits['test'].num_examples/BATCH_SIZE), epochs=EPOCH, validation_data=ds_test, verbose=1, use_multiprocessing=True, )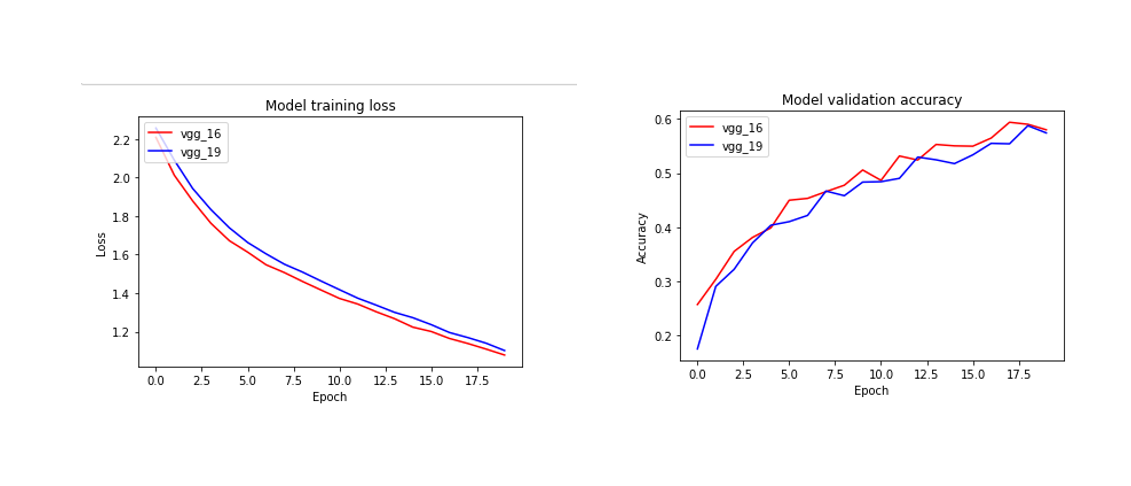
20에폭정도 했을때 loss가 정상적으로 잘 줄어들며 validation set으로 테스트 정확도 역시 증가하는 모습을 보여준다.
숙제
# 파이토치로도 구현 해보기
'pytorch & tensorflow' 카테고리의 다른 글
SRGAN Tensor flow 코드 구현 및 테스트 (4) 2021.10.07 resnet-36, resnet-50 구현 tensorflow (0) 2021.09.29 Pytorch mobile (0) 2021.06.07 Cycle gan webcam (0) 2021.06.07 전이학습 Transfer learning (0) 2021.06.07